





-1.jpg?width=296&height=196&name=man-wong-aSERflF331A-unsplash%20(1)-1.jpg)

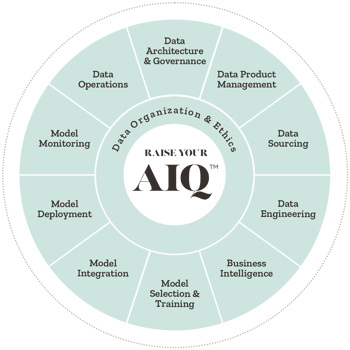

Data Engineering
Data Engineering is the practice of designing and building systems for collecting, storing, and analyzing data at scale.
Why does Data Engineering matter?
To derive insights and build products from data, companies must have the skills to acquire, reshape, and publish data. Data Engineers design, develop and optimize the flow of data within and between company systems and serve as the glue between application development and model selection and training. Data engineering makes data useful and accessible for consumers of data.

Tools
Experience with modern data-centric tools needed to move, ingest, store, query, transform, and clean data to support analytics and data modeling.
My organization has data teams that are experienced with programming languages (SQL, Python, R, Scala, Julia) used for querying data, transforming data, and training models.
Data query, transformation, and modeling data programming skills are used to retrieve and integrate data from various sources and train models.
My organization has data teams that are experienced with tools (e.g., data lakes, relational databases, APIs) and techniques used for data storage and access.
A subject matter expert is an individual with a deep understanding of a particular job, process, function, etc. They should be able to identify a business problem, its underlying intricacies, and use this information to justify the procurement of external data.
My organization efficiently tracks data as it arrives without manual intervention.
Given the immense amounts of data flowing through systems, it's important to automatically track it instead of relying on manual work which is error prone and expensive.
Practices
Defined practices for designing and building systems that collect, store, and analyze data at scale.
My organization addresses data quality errors with predefined policies.
Data Quality is a critical aspect of the data lifecycle. Issues in data quality can be looked at as opportunities - opportunities to address them at the root and then establish policies and procedures so as to prevent the same issues from coming up time and time again.
My organization generates processes to handle transient errors and recover during pipeline execution.
Transient errors are errors that are recoverable during process execution.
My organization has a data team with the ability to create high-quality lineage and manages table dependencies across the data pipeline.
Data Lineage is the process of understanding, recording, and visualizing data as it flows from data sources to consumption. This includes all transformations the data underwent undergoes along the way—how the data was transformed, what changed, and why. A dependency is a constraint that applies to or defines the relationship between data.
My organization creates standard components and documentation for cleaning data.
My organization has a data team that incrementally and efficiently processes high volumes of data as it arrives from files or streaming sources.
Big Data Streaming is a process in which data is quickly processed to extract real-time insights from it.
Programming
Experience using data-centric programming languages such as SQL, Python, R, Scala, and Julia to support analytics and data modeling.
My organization consistently embraces data engineering advances and leverages them at a re-usable component level on new projects.
Reusable components are data pipelines, integration and code implementing a "design / build for reuse" practice.
My organization's data team adheres to DevOps/DataOps/MLOps best practices in generating parameterized, automated deployments for the continuous delivery of data.
Continuous Delivery is the ability to get changes of all types—including new or updated data, new features, configuration changes and bug fixes—into production, or into the hands of users, safely and quickly in a sustainable way.
My organization confidently deploys data intensive applications such as data feeds and data APIs to production environment.
Learn more about Data Engineering
Data Engineering - AIQ Capability Overview
Data Engineering is the practice of designing and building systems for collecting, storing, and analyzing data at...