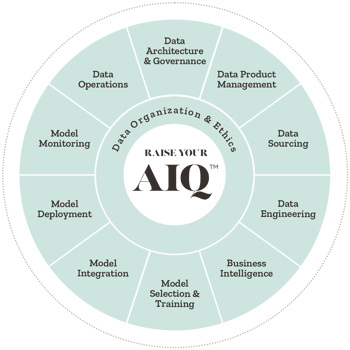
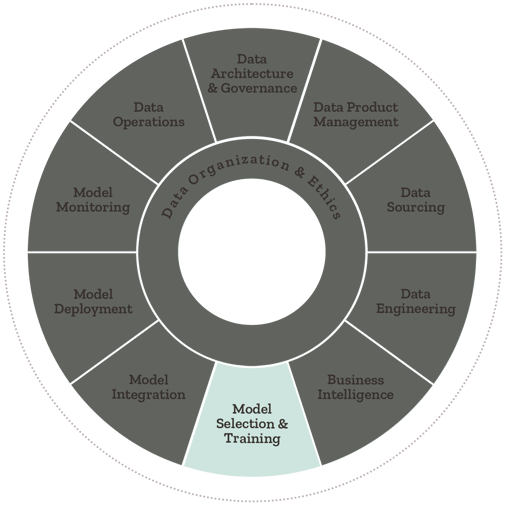
Model Selection & Training For Machine Learning
Synaptiq.ai's Chief Data Scientist, Dr. Tim Oates, talks about the importance of model selection and model training in...


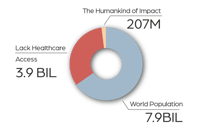
for the health of people
for the health of planet
for the health of business
|
FOR THE HEALTH OF PEOPLE: EQUITY
|
 |
|
“The work [with Synaptiq] is unprecedented in its scale and potential impact,” Mortenson Center’s Managing Director Laura MacDonald MacDonald said. “It ties together our center’s strengths in impact evaluation and sensor deployment to generate evidence that informs development tools, policy, and practice.”
|
| Read the Case Study ⇢ |
|
DATA STRATEGY
|
 |
|
A startup in digital health trained a risk model to open up a robust, precise, and scalable processing pipeline so providers could move faster, and patients could move with confidence after spinal surgery.
|
| Read the Case Study ⇢ |
|
PREDICTIVE ANALYTICS
|
 |
|
Thwart errors, relieve in-take form exhaustion, and build a more accurate data picture for patients in chronic pain? Those who prefer the natural albeit comprehensive path to health and wellness said: sign me up.
|
| Read the Case Study ⇢ |
|
MACHINE VISION
|
 |
|
Using a dynamic machine vision solution for detecting plaques in the carotid artery and providing care teams with rapid answers, saves lives with early disease detection and monitoring.
|
| Read the Case Study ⇢ |
|
INTELLIGENT AUTOMATION
|
-1.jpg?width=296&height=196&name=man-wong-aSERflF331A-unsplash%20(1)-1.jpg) |
|
This global law firm needed to be fast, adaptive, and provide unrivaled client service under pressure, intelligent automation did just that plus it made time for what matters most: meaningful human interactions.
|
| Read the Case Study ⇢ |
 |
|
Mushrooms, Goats, and Machine Learning: What do they all have in common? You may never know unless you get started exploring the fundamentals of Machine Learning with Dr. Tim Oates, Synaptiq's Chief Data Scientist. You can read and visualize his new book in Python, tinker with inputs, and practice machine learning techniques for free. |
| Start Chapter 1 Now ⇢ |